Today I’m going to talk about an idea I came up with in Boston, at Siggraph 2006, while attending a couple of very inspiring lectures given by Jason Mitchell, Gary McTaggart and Chris Green (Valve Software).
They have played over the years with a few different HDR rendering schemes and one of the key insights from their work is that we can happily de-couple exposure and tone mapping computations, deferring the latter to the next frame (actually this idea was first suggested to me by Simon Brown, that’s another story though..).
This simple concept allowed Valve guys to remove the classic full screen tone mapping rendering pass and to embed it directly in their single pass shaders using as exposure a value computed in the previous frames, thus completely eliminating the need to output HDR pixels.
Since at that time there was basically no hardware around that could handle MSAA on floating point render targets (oh gosh, just a few years ago!) they also got their HDR rendering implementation running with MSAA on relatively old hardware! Moreover their method executes tone mapping and MSAA resolve in the proper correct order (tone mapping first, followed by AA resolve) with no extra performance cost, something that a lot of modern games can’t still get right today.
If you were not aware of Valve’s method you are now probably asking yourself how they managed to compute an exposure value to be used in a tone mapping operator if no HDR data is ever dumped to the frame buffer. Through image segmentation techniques they ‘simply’ try to determine if the previous frame has been under or over exposed and a new exposure value is adjusted to compensate for problems with the previous frame(s).
While this method is very clever I have some problems with it. For instance many tone mapping operators require to determine exposure computing the average logarithmic luminance of a relevant portion of the image, but it’s not possible to reliably determine this value using Valve’s approach. HDR data is lost and while in theory we might be able to compute a plausible exposure value performing a search over multiple frames, in practice this is not easy at all. We might need to change the search direction over the exposure space to get closer to the exposure value we are looking for and this would make our image overall brightness swing back and forth for a few frames, like a pendulum around its rest configuration. Monotonic searches are possible too but they can get you only so close to the value we are looking for, especially if the image content is constantly changing!
Having debated this issue with current and former colleagues I know this is a controversial point, some agree with me, some think is not a big deal (and who knows, maybe they are even right!). On the other hand while playing Valve’s masterpieces (this method was first introduced in HL2 Lost Coast) I can’t stop noticing how sometime portions of the image are flat and seem to have lost their color details, giving me an overall flat and over or under saturated feeling (again, this is just a very personal and subjective opinion, feel free to disagree with me). This problem might be caused by a poor/overly simplified tone mapping operator (Valve games run great on not so powerful hardware and trade offs have to be made) and/or by an incorrect exposure (gotcha!).
After this long introduction I wouldn’t be surprised if you have already got my same idea: get rid of the exposure search through previous frames feedback and compute it the proper way!
The feedback/image segmentation method has been adopted because no HDR data is available, but even without re-introducing a floating point buffer (or some funky color space technique, see Christer Ericson’s blog entry about some of the work I did on Heavenly Sword and his very clever take on it) we can still generate the data we need using destination alpha. The idea is simple: compute logarithmic luminance on a per pixel basis, encode it in some special format and output it to the alpha channel.
If we decide to support a certain luminance range [2^-minLogLum, 2^maxLogLum] we can compress and encode logarithmic lumimance in our single pass shaders using some fairly simple math:
float invLogLumRange = 1 / (maxLogLum + minLogLum);
float logLumOffset = minLogLum * invLogLumRange;
float log_luminance = get_log_luminance( HDR_color ) * invLogLumRange + logLumOffset;
invLogLumRange and logLumOffset are constants that can precomputed so we just need a 3-way dot product, a scalar MADD and a logarithm to evaluate this formula. Explicitely clamping this expression between 0.0 and 1.0 is not necessary as the ROPs will do it for free anyway.
Since we only applied an affine transform to encode our log luminance is still correct to compute its average with multiple reduction passes as we do when we generate a mip map chain, down to a 1×1 render target, as long as we remember to invert the encoding to retrieve a proper average logarithm luminance value. Actually it’s a good idea to do this last step on the CPU (since this computation can be deferred one or two framaes we should be able to lock this specific resource and read it back with the CPU without stalling either processor) so that we can set our exposure for the next frame color pass as a pixel shader constant, removing any extra math and texture sampling from the 1×1 log luminance texture.
Unfortunately almost no trick comes for free, if we use destination alpha to encode logarithmic luminance we can’t use it for other useful operations such as alpha blending and alpha to coverage (alpha test is still doable as long as we implement it in our shaders invoking kill() or discard() ). I’m not particularly worried about alpha blending, we can simply compute our average logarithmic luminance before we render transparent objects, those won’t contribute to the exposure computations but I suspect this is not a big deal in many cases. The same trick can be applied for alpha to coverage objects, though I wouldn’t advocate it if we know we are going to render a lot of alpha coverage stuff on screen (for example think about lots of trees, it’s not probably going to work well if we are working on a Robin Hood game..)
Now we are free to implement a lot of different tone mapping operators in our single pass shaders, even if we are working on a deferred renderer, as long as its architecture can shade an opaque pixel for an arbitrary number of lights in a single pass, like in the ingenious scheme proposed by Pål-Kristian Engstad at Naughty Dog.
One last note: while I love (and I always will..) finding new and unexpected ways to use graphics hardware it’s clear to me things are going to change soon, very soon. Shaders allow us to do almost anything, but they are still encapsulated in a rendering pipeline that dates back to the late 80s and that has gone almost unchanged for the last twenty years. When I was a student I once used to write my own rendering pipeline (my beloved Amiga didn’t have a GPU..) which wasn’t always based on z-buffer and rasterization (though I wrote so many rasterizers I lost count of them..) and I’m glad of the cyclical nature of hardware development as we are now about to go back to the future and once again develop our own custom rendering architecture on top of recent years advancements. Only this time is going to be even more fun!







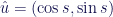
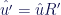




 .
.