Here’s a nice trick for whoever has implemented (as a single pass that operates in screen space) deferred cascaded/parallel split shadow maps on hardware that does not allow to index texture samplers associated with different view space splits.
One way to address this issue is to store multiple shadow maps (usually one per split) into a single depth texture, then the correct shadow map can be sampled computing (per pixel!) all the possible texturing coordinates per each split and selecting the right one through predication. Another method quite similar to the first one involves removing the predication step and replacing it with dynamic branches. This can end up being faster the the predication method on some hardware, especially if we have to select the correct sampling coordinates among many splits.
But what if we want to take a variable amount of PCF samples per split without using dynamic branching? (I love DB but it’s not exactly fast on every hardware out there, is up to you decide when it’s a good idea to use it or not).
It’s indeed possible to take a dynamic number of samples per pixel using an hardware feature that was initially introduced by NVIDIA to accelerate…stencil shadows! (ironic, isn’t it?)
I am talking about the depth bounds test which is a ‘new’ kind of depth test that does not involve the depth value of the incoming fragment but the depth value written in the depth buffer at the screen space coordinates determined by the incoming fragment. This depth value is checked against some min and max depth values; when it’s not contained within a depth region the incoming fragment gets discarded. Setting the depth min and max values around a shadow map split is a easy way to (early!) reject all those pixels that don’t fall within a certain depth interval. At this point we don’t need to compute multiple texture coordinates per pixel anymore, we can directly evaluate the sampling coordinates that map a pixel onto the shadow map associated with the current split and take a certain number of PCFed samples from it.
Multiple rendering passes are obviously needed (one per split) to generate an occlusion term for the whole image but this is not generally a big problem cause the depth bounds test can happen before our pixel shader is evaluated and multiple pixels can be early rejected per clock via hierarchical z-culling (this approach won’t be fast if our image contains a lot of alpha tested geometry as this kind of geometry doesn’t not generate occluders in the on chip hi-z representation forcing the hardware to evaluate the pixel shader and eventually to reject a shaded pixel).
The multipass approach can be a win cause we can now use a different shader per shadow map split making possible to take a variable number of samples per split: typically we want to take more samples for pixels that are closer to the camera and less samples for distant objects. Another indirect advantage of this technique is the improved texture cache usage as the GPU won’t jump from a shadow map to another shadow map anymore. In fact with the original method each pixel can map anywhere in our big shadow map, while going multipass will force the GPU to sample locations within the same shadow map/parallel split.
I like this trick cause even though it doesn’t work on every GPU out there it puts to some use hardware that was designed to accelerate a completely different shadowing technique. Hope you enjoyed this post and as usual comments, ideas and constructive critics are welcome!
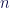


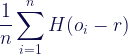





![\begin{array}{ccc} \displaystyle\lim_{k \to +\infty}\frac{1}{ne^{kr}}\sum_{i=1}^{n}\frac{e^{ko_i}}{e^{k(o_i - r)}+1} &\approx&\displaystyle\lim_{k \to +\infty}\frac{1}{ne^{kr}}\sum_{i=1}^{n}e^{ko_i} \\ &\equiv&\displaystyle\lim_{k \to +\infty}\frac{E[e^{ko}]}{e^{kr}} \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bccc%7D+%5Cdisplaystyle%5Clim_%7Bk+%5Cto+%2B%5Cinfty%7D%5Cfrac%7B1%7D%7Bne%5E%7Bkr%7D%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7Be%5E%7Bko_i%7D%7D%7Be%5E%7Bk%28o_i+-+r%29%7D%2B1%7D+%26%5Capprox%26%5Cdisplaystyle%5Clim_%7Bk+%5Cto+%2B%5Cinfty%7D%5Cfrac%7B1%7D%7Bne%5E%7Bkr%7D%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7De%5E%7Bko_i%7D+%5C%5C+%26%5Cequiv%26%5Cdisplaystyle%5Clim_%7Bk+%5Cto+%2B%5Cinfty%7D%5Cfrac%7BE%5Be%5E%7Bko%7D%5D%7D%7Be%5E%7Bkr%7D%7D+%5C%5C+%5Cend%7Barray%7D&bg=ffffff&fg=0c0b47&s=1&c=20201002)
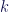
![\displaystyle \frac{E[e^{ko}]}{e^{kr}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7BE%5Be%5E%7Bko%7D%5D%7D%7Be%5E%7Bkr%7D%7D&bg=ffffff&fg=0c0b47&s=2&c=20201002)
